ArangoDB v3.11 reached End of Life (EOL) and is no longer supported.
This documentation is outdated. Please see the most recent stable version.
Features and Improvements in ArangoDB 3.11
Improved performance and reporting for AQL queries, new caching features for indexed data, improvements to the web interface
The following list shows in detail which features have been added or improved in ArangoDB 3.11. ArangoDB 3.11 also contains several bug fixes that are not listed here.
ArangoSearch
Late materialization improvements
The number of disk reads required when executing search queries with late materialization optimizations applied has been reduced so that less data needs to be requested from the RocksDB storage engine.
ArangoSearch column cache (Enterprise Edition)
arangosearch Views support new caching options.
Introduced in: v3.9.5, v3.10.2
You can enable the new
cacheoption for individual View links or fields to always cache field normalization values in memory. This can improve the performance of scoring and ranking queries.It also enables caching of auxiliary data used for querying fields that are indexed with Geo Analyzers. This can improve the performance of geo-spatial queries.
You can enable the new
cacheoption in the definition of astoredValuesView property to always cache stored values in memory. This can improve the query performance if stored values are involved.
Introduced in: v3.9.6, v3.10.2
You can enable the new
primarySortCacheView property to always cache the primary sort columns in memory. This can improve the performance of queries that utilize the primary sort order.You can enable the new
primaryKeyCacheView property to always cache the primary key column in memory. This can improve the performance of queries that return many documents.
Inverted indexes also support similar new caching options.
Introduced in: v3.10.2
A new
cacheoption for inverted indexes as the default or for specificfieldsto always cache field normalization values and Geo Analyzer auxiliary data in memory.A new
cacheoption per object in the definition of thestoredValueselements to always cache stored values in memory.A new
cacheoption in theprimarySortproperty to always cache the primary sort columns in memory.A new
primaryKeyCacheproperty for inverted indexes to always cache the primary key column in memory.
The cache size can be controlled with the new --arangosearch.columns-cache-limit
startup option and monitored via the new arangodb_search_columns_cache_size
metric.
ArangoSearch caching is only available in the Enterprise Edition.
See Optimizing View and inverted index query performance for examples.
Analyzers
geo_s2 Analyzer (Enterprise Edition)
Introduced in: v3.10.5
This new Analyzer lets you index GeoJSON data with inverted indexes or Views
similar to the existing geojson Analyzer, but it internally uses a format for
storing the geo-spatial data that is more efficient.
You can choose between different formats to make a tradeoff between the size on disk, the precision, and query performance:
- 8 bytes per coordinate pair using 4-byte integer values, with limited precision.
- 16 bytes per coordinate pair using 8-byte floating-point values, which is still
more compact than the VelocyPack format used by the
geojsonAnalyzer - 24 bytes per coordinate pair using the native Google S2 format to reduce the number of computations necessary when you execute geo-spatial queries.
This feature is only available in the Enterprise Edition.
See Analyzers for details.
Web interface
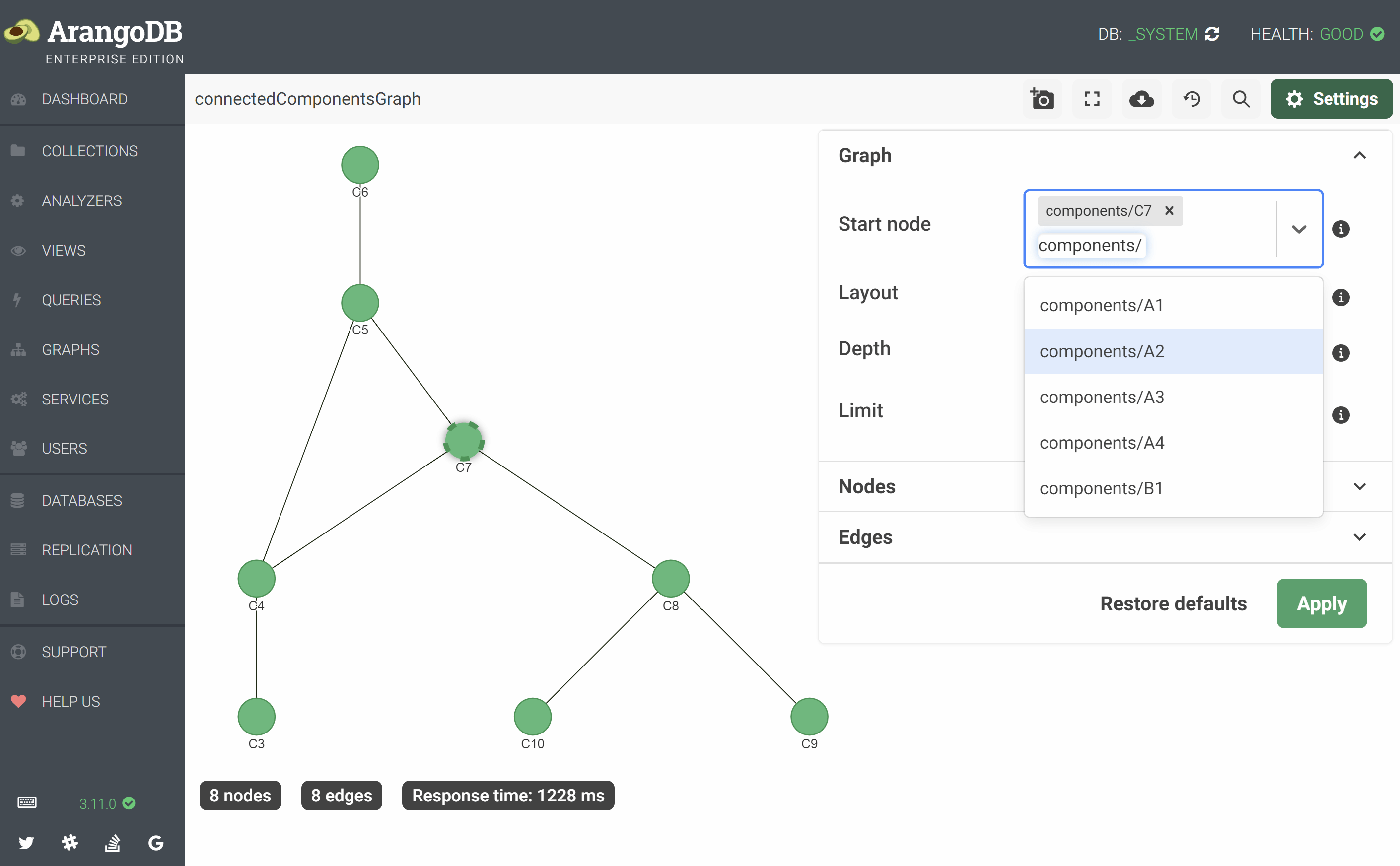
New graph viewer
The graph viewer for visualizing named graphs has been reimplemented based on the vis.js library, the interface has been redesigned to be cleaner and rewritten to use the React framework, and the overall performance has been improved.
The available Layout algorithms are forceAtlas2 and hierarchical. Force-based layouts try to avoid overlaps while grouping adjacent nodes together. The new hierarchical layout is useful for strict topologies like trees.
A new feature is the ability to search the visible graph to center a specific vertex. Another quality-of-life improvement is the Start node setting listing the graph’s vertex collections and the available document keys, that you can also search by.
You can still switch to the old graph viewer if desired.
See the Graph Viewer documentation for details.
search-alias Views
The 3.11 release of ArangoDB introduces a new web interface for Views that lets
you to create and manage search-alias Views.
Through this dialog, you can easily create a new View and add to it one or more inverted indexes from your collections that you could otherwise do via the HTTP or JavaScript API.
When opening your newly created View, you can copy mutable properties from
previously created search-alias Views, providing a convenient way to apply
the same settings to multiple Views. In addition, the JSON editor offers the
option to directly write the definition of your View in JSON format.
For more information, see the detailed guide.
arangosearch Views
The existing way of creating and managing arangosearch Views through the
web interface has been redesigned, offering a more straightforward approach to add
or modify the definition of your View. The settings, links, and JSON editor have
been merged into a single page, allowing for a much quicker workflow.
For more information, see the detailed guide.
Inverted indexes
The web interface now includes the option for creating inverted indexes on collections. You can set all the properties directly in the web interface, which previously required the JavaScript or HTTP API. It also offers an editor where you can write the definition of your inverted index in JSON format.
New sorting mechanism and search box for Saved Queries
When working with Saved Queries in the web interface, you can now configure their sort order so that your saved queries are listed by the date they were last modified. This is particularly helpful when you have a large amount of saved custom queries and want to see which ones have been created or used recently.
In addition, the web interface also offers a search box which helps you quickly find the query you’re looking for.
AQL
Parallel gather
On Coordinators in cluster deployments, results from different DB-Servers are
combined into a stream of results. This process is called gathering. It shows as
GatherNode nodes in the execution plan of AQL queries.
Previously, a cluster AQL query could only parallelize a GatherNode if the
DB-Server query part above it (in terms of query execution plan layout) was a
terminal part of the query. That means that it was not allowed for other nodes of
type ScatterNode, GatherNode, or DistributeNode to be present in the query.
Modification queries were also not allowed to use parallel gather unless the
--query.parallelize-gather-writes startup option was enabled, which defaulted
to false.
From v3.11.0 onward, these limitations are removed so that parallel gather can be
used in almost all queries. As a result, the feature is enabled by default and
the --query.parallelize-gather-writes startup option is now obsolete. You can
still disable the optimization by disabling the parallelize-gather AQL
optimizer rule.
The only case where parallel gather is not supported is when using traversals, although there are some exceptions for Disjoint SmartGraphs where the traversal can run completely on the local DB-Server (only available in the Enterprise Edition).
The parallel gather optimization can not only speed up queries quite significantly,
but also overcome issues with the previous serial processing within GatherNode
nodes, which could lead to high memory usage on Coordinators caused by buffering
of documents for other shards, and timeouts on some DB-Servers because query parts
were idle for too long.
Optimized access of last element in traversals
If you use a FOR operation for an AQL graph traversal like FOR v, e, p IN ...
and later access the last vertex or edge via the path variable p, like
FILTER p.vertices[-1].name == "ArangoDB" or FILTER p.edges[-1].weight > 5,
the access is transformed to use the vertex variable v or edge variable e
instead, like FILTER v.name == "ArangoDB" or FILTER e.weight > 5. This is
cheaper to compute because the path variable p may not need to be computed at
all, and it can enable further optimizations that are not possible on p.
The new optimize-traversal-last-element-access optimization rule appears in
query execution plans if this optimization is applied.
Faster bulk INSERT operations in clusters
AQL INSERT operations that insert multiple documents can now be faster in
cluster deployments by avoiding unnecessary overhead that AQL queries typically
require for the setup and shutdown in a cluster, as well as for the internal
batching.
This improvement also decreases the number of HTTP requests to the DB-Servers.
Instead of batching the array of documents (with a default batch size of 1000),
a single request per DB-Server is used internally to transfer the data.
The optimization brings the AQL INSERT performance close to the performance of
the specialized HTTP API for creating multiple documents.
The pattern that is recognized by the optimizer is as follows:
FOR doc IN <docs> INSERT doc INTO collection<docs> can either be a bind parameter, a variable, or an array literal.
The value needs to be an array of objects and be known at query compile time.
Query String (43 chars, cacheable: false):
FOR doc IN @docs INSERT doc INTO collection
Execution plan:
Id NodeType Site Est. Comment
1 SingletonNode COOR 1 * ROOT
2 CalculationNode COOR 1 - LET #2 = [ { "value" : 1 }, { "value" : 2 }, { "value" : 3 } ] /* json expression */ /* const assignment */
5 MultipleRemoteModificationNode COOR 3 - FOR doc IN #2 INSERT doc IN collection
Indexes used:
none
Optimization rules applied:
Id RuleName
1 remove-data-modification-out-variables
2 optimize-cluster-multiple-document-operationsThe query runs completely on the Coordinator. The MultipleRemoteModificationNode
performs a bulk document insert for the whole input array in one go, internally
using a transaction that is more lightweight for transferring the data to the
DB-Servers than a regular AQL query.
Without the optimization, the Coordinator requests data from the DB-Servers
(GatherNode), but the DB-Servers have to contact the Coordinator in turn to
request their data (DistributeNode), involving a network request for every
batch of documents:
Execution plan:
Id NodeType Site Est. Comment
1 SingletonNode COOR 1 * ROOT
2 CalculationNode COOR 1 - LET #2 = [ { "value" : 1 }, { "value" : 2 }, { "value" : 3 } ] /* json expression */ /* const assignment */
3 EnumerateListNode COOR 3 - FOR doc IN #2 /* list iteration */
9 CalculationNode COOR 3 - LET #4 = MAKE_DISTRIBUTE_INPUT_WITH_KEY_CREATION(doc, null, { "allowSpecifiedKeys" : false, "ignoreErrors" : false, "collection" : "collection" }) /* simple expression */
5 DistributeNode COOR 3 - DISTRIBUTE #4
6 RemoteNode DBS 3 - REMOTE
4 InsertNode DBS 0 - INSERT #4 IN collection
7 RemoteNode COOR 0 - REMOTE
8 GatherNode COOR 0 - GATHER /* parallel, unsorted */The new optimize-cluster-multiple-document-operations optimizer rule that
enables the optimization is only applied if there is no RETURN operation,
which means you cannot use RETURN NEW or similar to access the new documents
including their document keys. Additionally, all preceding calculations must be
constant, which excludes any subqueries that read documents.
See the list of optimizer rules for details.
Index cache refilling
The edge cache refilling
feature introduced in v3.9.6 and v3.10.2 is no longer experimental. From v3.11.0
onward, it is called index cache refilling and is not limited to edge caches
anymore, but also supports in-memory hash caches of persistent indexes
(persistent indexes with the cacheEnabled option set to true).
This new feature automatically refills the in-memory index caches. When documents (including edges) are added, modified, or removed and if this affects an edge index or cache-enabled persistent indexes, these changes are tracked and a background thread tries to update the index caches accordingly if the feature is enabled, by adding new, updating existing, or deleting and refilling cache entries.
You can enable it for individual INSERT, UPDATE, REPLACE, and REMOVE
operations in AQL queries (using OPTIONS { refillIndexCaches: true }), for
individual document API requests that insert, update, replace, or remove single
or multiple documents (by setting refillIndexCaches=true as query
parameter), as well as enable it by default using the new
--rocksdb.auto-refill-index-caches-on-modify startup option.
The new --rocksdb.auto-refill-index-caches-queue-capacity startup option
restricts how many index cache entries the background thread can queue at most.
This limits the memory usage for the case of the background thread being slower
than other operations that invalidate index cache entries.
The background refilling is done on a best-effort basis and not guaranteed to succeed, for example, if there is no memory available for the cache subsystem, or during cache grow/shrink operations. A background thread is used so that foreground write operations are not slowed down by a lot. It may still cause additional I/O activity to look up data from the storage engine to repopulate the cache.
In addition to refilling the index caches, the caches can also automatically be
seeded on server startup. Use the new --rocksdb.auto-fill-index-caches-on-startup
startup option to enable this feature. It may cause additional CPU and I/O load.
You can limit how many index filling operations can execute concurrently with the
--rocksdb.max-concurrent-index-fill-tasks option. The lower this number, the
lower the impact of the cache filling, but the longer it takes to complete.
The following metrics are available:
| Label | Description |
|---|---|
rocksdb_cache_auto_refill_loaded_total | Total number of queued items for in-memory index caches refilling. |
rocksdb_cache_auto_refill_dropped_total | Total number of dropped items for in-memory index caches refilling. |
rocksdb_cache_full_index_refills_total | Total number of in-memory index caches refill operations for entire indexes. |
This feature is experimental.
Also see:
- AQL
INSERToperation - AQL
UPDATEoperation - AQL
REPLACEoperation - AQL
REMOVEoperation - Document HTTP API
- Index cache refill options
Retry request for result batch
You can retry the request for the latest result batch of an AQL query cursor if
you enable the new allowRetry query option. See
API Changes in ArangoDB 3.11
for details.
COLLECT ... INTO can use hash method
Grouping with the COLLECT operation supports two different methods, hash and
sorted. For COLLECT operations with an INTO clause, only the sorted method
was previously supported, but the hash variant has been extended to now support
INTO clauses as well.
FOR i IN 1..10
COLLECT v = i % 2 INTO group // OPTIONS { method: "hash" }
SORT null
RETURN { v, group }Execution plan:
Id NodeType Est. Comment
1 SingletonNode 1 * ROOT
2 CalculationNode 1 - LET #3 = 1 .. 10 /* range */ /* simple expression */
3 EnumerateListNode 10 - FOR i IN #3 /* list iteration */
4 CalculationNode 10 - LET #5 = (i % 2) /* simple expression */
5 CollectNode 8 - COLLECT v = #5 INTO group KEEP i /* hash */
8 CalculationNode 8 - LET #9 = { "v" : v, "group" : group } /* simple expression */
9 ReturnNode 8 - RETURN #9The query optimizer automatically chooses the hash method for the above
example query, but you can also specify your preferred method explicitly.
See the COLLECT options for details.
K_SHORTEST_PATHS performance improvements
The K_SHORTEST_PATHS graph algorithm in AQL has been refactored in ArangoDB 3.11,
resulting in major performance improvements. The query now returns the
shortest paths between two documents in a graph up to 100 times faster.
Added AQL functions
Added the DATE_ISOWEEKYEAR() function that returns the ISO week number,
like DATE_ISOWEEK() does, but also the year it belongs to:
RETURN DATE_ISOWEEKYEAR("2023-01-01") // { "week": 52, "year": 2022 }
See AQL Date functions for details.
Added the SHA256() function that calculates the SHA256 checksum for a string
and returns it in a hexadecimal string representation.
RETURN SHA256("ArangoDB") // "acbd84398a61fcc6fd784f7e16c32e02a0087fd5d631421bf7b5ede5db7fda31"
See AQL String functions for details.
Extended query explain statistics
Introduced in: v3.10.4
The query explain result now includes the peak memory usage and execution time. This helps finding queries that use a lot of memory or take long to build the execution plan.
The additional statistics are displayed at the end of the output in the
web interface (using the Explain button in the QUERIES section) and in
arangosh (using db._explain()):
44 rule(s) executed, 1 plan(s) created, peak mem [b]: 32768, exec time [s]: 0.00214
The HTTP API returns the extended statistics in the stats attribute when you
use the POST /_api/explain endpoint:
{
...
"stats": {
"rulesExecuted": 44,
"rulesSkipped": 0,
"plansCreated": 1,
"peakMemoryUsage": 32768,
"executionTime": 0.00241307167840004
}
}
Also see:
Extended peak memory usage reporting
The peak memory usage of AQL queries is now also reported for running queries and slow queries.
In the web interface, you can find the Peak memory usage column in the QUERIES section, in the Running Queries and Slow Query History tabs.
In the JavaScript and HTTP APIs, the value is reported as peakMemoryUsage.
See API Changes in ArangoDB 3.11.
Number of cluster requests in profiling output
Introduced in: v3.9.5, v3.10.2
The query profiling output in the web interface and arangosh now shows the
number of HTTP requests for queries that you run against cluster deployments in
the Query Statistics:
Query String (33 chars, cacheable: false):
FOR doc IN coll
RETURN doc._key
Execution plan:
Id NodeType Site Calls Items Filtered Runtime [s] Comment
1 SingletonNode DBS 3 3 0 0.00024 * ROOT
9 IndexNode DBS 3 0 0 0.00060 - FOR doc IN coll /* primary index scan, index only (projections: `_key`), 3 shard(s) */
3 CalculationNode DBS 3 0 0 0.00025 - LET #1 = doc.`_key` /* attribute expression */ /* collections used: doc : coll */
7 RemoteNode COOR 6 0 0 0.00227 - REMOTE
8 GatherNode COOR 2 0 0 0.00209 - GATHER /* parallel, unsorted */
4 ReturnNode COOR 2 0 0 0.00008 - RETURN #1
Indexes used:
By Name Type Collection Unique Sparse Cache Selectivity Fields Stored values Ranges
9 primary primary coll true false false 100.00 % [ `_key` ] [ ] *
Optimization rules applied:
Id RuleName
1 scatter-in-cluster
2 distribute-filtercalc-to-cluster
3 remove-unnecessary-remote-scatter
4 reduce-extraction-to-projection
5 parallelize-gather
Query Statistics:
Writes Exec Writes Ign Scan Full Scan Index Cache Hits/Misses Filtered Requests Peak Mem [b] Exec Time [s]
0 0 0 0 0 / 0 0 9 32768 0.00564New stage in query profiling output
Introduced in: v3.10.3
The query profiling output has a new instantiating executors stage.
The time spent in this stage is the time needed to create the query executors
from the final query execution time. In cluster mode, this stage also includes
the time needed for physically distributing the query snippets to the
participating DB-Servers. Previously, the time spent for instantiating executors
and the physical distribution was contained in the optimizing plan stage.
Query Profile:
Query Stage Duration [s]
initializing 0.00001
parsing 0.00009
optimizing ast 0.00001
loading collections 0.00001
instantiating plan 0.00004
optimizing plan 0.00088
instantiating executors 0.00153
executing 1.27349
finalizing 0.00091
Limit for the normalization of FILTER conditions
Converting complex AQL FILTER conditions with a lot of logical branches
(AND, OR, NOT) into the internal DNF (disjunctive normal form) format can
take a large amount of processing time and memory. The new maxDNFConditionMembers
query option is a threshold for the maximum number of OR sub-nodes in the
internal representation and defaults to 786432.
You can also set the threshold globally instead of per query with the
--query.max-dnf-condition-members startup option.
If the threshold is hit, the query continues with a simplified representation of the condition, which is not usable in index lookups. However, this should still be better than overusing memory or taking a very long time to compute the DNF version.
Server options
Telemetrics
Starting with version 3.11, ArangoDB automatically gathers information on how it is used and the features being utilized. This data is used to identify the primary usage patterns and features, and to measure their adoption rate.
The information collected by ArangoDB is anonymous and purely statistical. It does not contain any personal information like usernames or IP addresses, nor any content of the documents stored in ArangoDB. This means that your privacy is protected, and that there is no risk of your data being compromised.
If for any reason you prefer not to share usage statistics with ArangoDB, you
can easily disable this feature by setting the new --server.telemetrics-api
startup option to false. The default value is true.
For a detailed list of what anonymous metrics ArangoDB collects see Telemetrics.
Extended naming constraints for collections, Views, and indexes
In ArangoDB 3.9, the --database.extended-names-databases startup option was
added to optionally allow database names to contain most UTF-8 characters.
The startup option has been renamed to --database.extended-names in 3.11 and
now controls whether you want to use the extended naming constraints for
database, collection, View, and index names.
This feature is experimental in ArangoDB 3.11, but will become the norm in a future version.
Running the server with the option enabled provides support for extended names that are not comprised within the ASCII table, such as Japanese or Arabic letters, emojis, letters with accentuation. Also, many ASCII characters that were formerly banned by the traditional naming constraints are now accepted.
Example collection, View, and index names that can be used with the new extended
constraints: España, 😀, 犬, كلب, @abc123, København, München,
Бишкек, abc? <> 123!
Using extended collection and View names in the JavaScript API such as in arangosh or Foxx may require using the square bracket notation instead of the dot notation for property access depending on the characters you use:
db._create("🥑~колекція =)");
db.🥑~колекція =).properties(); // dot notation (syntax error)
db["🥑~колекція =)"].properties() // square bracket notation
Using extended collection and View names in AQL queries requires wrapping the name in backticks or forward ticks (see AQL Syntax):
FOR doc IN `🥑~колекція =)`
RETURN docWhen using extended names, any Unicode characters in names need to be NFC-normalized . If you try to create a database, collection, View, or index with a non-NFC-normalized name, the server rejects it.
The ArangoDB web interface as well as the arangobench, arangodump, arangoexport, arangoimport, arangorestore, and arangosh client tools ship with support for the extended naming constraints, but they require you to provide NFC-normalized names.
Note that the default value for --database.extended-names is false
for compatibility with existing client drivers and applications that only support
ASCII names according to the traditional naming constraints used in previous
ArangoDB versions. Enabling the feature may lead to incompatibilities up to the
ArangoDB instance becoming inaccessible for such drivers and client applications.
Please be aware that dumps containing extended names cannot be restored into older versions that only support the traditional naming constraints. In a cluster setup, it is required to use the same naming constraints for all Coordinators and DB-Servers of the cluster. Otherwise, the startup is refused. In DC2DC setups, it is also required to use the same naming constraints for both datacenters to avoid incompatibilities.
Also see:
- Collection names
- View names
- Index names have the same character restrictions as collection names
Verify .sst files
The new --rocksdb.verify-sst startup option lets you validate the .sst files
currently contained in the database directory on startup. If set to true,
on startup, all SST files in the engine-rocksdb folder in the database
directory are validated, then the process finishes execution.
The default value is false.
Support for additional value suffixes
Numeric startup options support suffixes like m (megabytes) and GiB (gibibytes)
to make it easier to specify values that are expected in bytes. The following
suffixes are now also supported:
tib,TiB,TIB: tebibytes (factor 10244)t,tb,T,TB: terabytes (factor 10004)b,B: bytes (factor 1)
Example: arangod --rocksdb.total-write-buffer-size 2TiB
See Suffixes for numeric options for details.
Configurable status code if write concern not fulfilled
In cluster deployments, you can use a replication factor greater than 1 for
collections. This creates additional shard replicas for redundancy. For write
operations to these collections, you can define how many replicas need to
acknowledge the write for the operation to succeed. This option is called the
write concern. If there are not enough in-sync replicas available, the
write concern cannot be fulfilled. An error with the HTTP 403 Forbidden
status code is returned immediately in this case.
You can now change the status code via the new
--cluster.failed-write-concern-status-code startup option. It defaults to 403
but you can set it to 503 to use an HTTP 503 Service Unavailable status code
instead. This signals client applications that it is a temporary error.
Note that no automatic retry of the operation is attempted by the cluster if you
set the startup option to 503. It only changes the status code to one that
doesn’t signal a permanent error like 403 does.
It is up to client applications to retry the operation.
RocksDB BLOB storage (experimental)
From version 3.11 onward, ArangoDB can make use of RocksDB’s integrated BLOB (binary large object) storage for larger documents, called BlobDB. This is currently an experimental feature, not supported and should not be used in production.
BlobDB is an integral part of RocksDB and provides a key-value separation: large values are stored in dedicated BLOB files, and only a small pointer to them is stored in the LSM tree’s SST files. Storing values separate from the keys means that the values do no need to be moved through the LSM tree by the compaction. This reduces write amplification and is especially beneficial for large values.
When the option is enabled in ArangoDB, the key-value separation is used for the documents column family, because large values are mostly to be expected here. The cutoff value for the key-value separation is configurable by a startup option, i.e. the administrator can set a size limit for values from which onwards they are offloaded to separate BLOB files. This allows storing small documents inline with the keys as before, but still benefit from reduced write amplification for larger documents.
BlobDB is disabled by default in ArangoDB 3.11. Using BlobDB in ArangoDB is experimental and not recommended in production. It is made available as an experimental feature so that further tests and tuning can be done by interested parties. Future versions of ArangoDB may declare the feature production-ready and even enable BlobDB by default.
There are currently a few caveats when using BlobDB in ArangoDB:
- Even though BlobDB can help reduce the write amplification, it may increase the read amplification and may worsen the read performance for some workloads.
- The various tuning parameters that BlobDB offers are made available in ArangoDB, but the current default settings for the BlobDB tuning options are not ideal for many use cases and need to be adjusted by administrators first.
- It is very likely that the default settings for the BlobDB tuning options will change in future versions of ArangoDB.
- Memory and disk usage patterns are different to that of versions running without BlobDB enabled. It is very likely that memory limits and disk capacity may need to be adjusted.
- Some metrics for observing RocksDB do not react properly when BlobDB is in use.
- The built-in throttling mechanism for controlling the write-throughput slows down writes too much when BlobDB is used. This can be circumvented with tuning parameters, but the defaults may be too aggressive.
The following experimental startup options have been added in ArangoDB 3.11 to enable and configure BlobDB:
--rocksdb.enable-blob-files: Enable the usage of BLOB files for the documents column family. This option defaults tofalse. All following options are only relevant if this option is set totrue.--rocksdb.min-blob-size: Size threshold for storing large documents in BLOB files (in bytes, 0 = store all documents in BLOB files).--rocksdb.blob-file-size: Size limit for BLOB files in the documents column family (in bytes). Note that RocksDB counts the size of uncompressed BLOBs before checking if a new BLOB file needs to be started, even though the BLOB may be compressed and end up much smaller than uncompressed.--rocksdb.blob-compression-type: Compression algorithm to use for BLOB data in the documents column family.--rocksdb.enable-blob-garbage-collection: Enable BLOB garbage collection during compaction in the documents column family.--rocksdb.blob-garbage-collection-age-cutoff: Age cutoff for garbage collecting BLOB files in the documents column family (percentage value from 0 to 1 determines how many BLOB files are garbage collected during compaction).--rocksdb.blob-garbage-collection-force-threshold: Garbage ratio threshold for scheduling targeted compactions for the oldest BLOB files in the documents column family.
Note that ArangoDB’s built-in throttling mechanism that automatically adjusts the write rate for RocksDB may need to be reconfigured as well to see the benefits of BlobDB. The relevant startup options for the throttle are:
--rocksdb.throttle-lower-bound-bps--rocksdb.throttle-max-write-rate--rocksdb.throttle-slow-down-writes-trigger
--query.max-dnf-condition-members option
See Limit for the normalization of FILTER conditions.
--rocksdb.reserve-file-metadata-memory option
This new startup option controls whether to account for .sst file metadata
memory in the block cache.
ArangoSearch column cache limit
Introduced in: v3.9.5, v3.10.2
The new --arangosearch.columns-cache-limit startup option lets you control how
much memory (in bytes) the ArangoSearch column cache
is allowed to use.
Introduced in: v3.10.6
You can reduce the memory usage of the column cache in cluster deployments by
only using the cache for leader shards with the new
--arangosearch.columns-cache-only-leader startup option.
It is disabled by default, which means followers also maintain a column cache.
AQL query logging
Introduced in: v3.9.5, v3.10.2
There are three new startup options to configure how AQL queries are logged:
--query.log-failedfor logging all failed AQL queries, to be used during development or to catch unexpected failed queries in production (off by default)--query.log-memory-usage-thresholdto define a peak memory threshold from which on a warning is logged for AQL queries that exceed it (default: 4 GB)--query.max-artifact-log-lengthfor controlling the length of logged query strings and bind parameter values. Both are truncated to 4096 bytes by default.
Index cache refill options
Introduced in: v3.9.6, v3.10.2
--rocksdb.auto-refill-index-caches-on-modify: Whether to automatically (re-)fill in-memory index cache entries on insert/update/replace operations by default. Default:false.--rocksdb.auto-refill-index-caches-queue-capacity: How many changes can be queued at most for automatically refilling the index cache. Default:131072.--rocksdb.auto-fill-index-caches-on-startup: Whether to automatically fill the in-memory index cache with entries on server startup. Default:false.--rocksdb.max-concurrent-index-fill-tasks: The maximum number of index fill tasks that can run concurrently on server startup. Default: the number of cores divided by 8, but at least1.
Introduced in: v3.9.10, v3.10.5
--rocksdb.auto-refill-index-caches-on-followers: Control whether automatic refilling of in-memory caches should happen on followers or only leaders. The default value istrue, i.e. refilling happens on followers, too.
Cluster supervision options
Introduced in: v3.9.6, v3.10.2
The following new options allow you to delay supervision actions for a configurable amount of time. This is desirable in case DB-Servers are restarted or fail and come back quickly because it gives the cluster a chance to get in sync and fully resilient without deploying additional shard replicas and thus without causing any data imbalance:
--agency.supervision-delay-add-follower: The delay in supervision, before an AddFollower job is executed (in seconds).--agency.supervision-delay-failed-follower: The delay in supervision, before a FailedFollower job is executed (in seconds).
Introduced in: v3.9.7, v3.10.2
A --agency.supervision-failed-leader-adds-follower startup option has been
added with a default of true (behavior as before). If you set this option to
false, a FailedLeader job does not automatically configure a new shard
follower, thereby preventing unnecessary network traffic, CPU load, and I/O load
for the case that the server comes back quickly. If the server has permanently
failed, an AddFollower job is created anyway eventually, as governed by the
--agency.supervision-delay-add-follower option.
RocksDB Bloom filter option
Introduced in: v3.10.3
A new --rocksdb.bloom-filter-bits-per-key startup option has been added to
configure the number of bits to use per key in a Bloom filter.
The default value is 10, which is downwards-compatible to the previously
hard-coded value.
Disable user-defined AQL functions
Introduced in: v3.10.4
The new --javascript.user-defined-functions startup option lets you disable
user-defined AQL functions so that no user-defined JavaScript code of
UDFs runs on the server. This can be useful to close off
a potential attack vector in case no user-defined AQL functions are used.
Also see Server security options.
Option to disable Foxx
Introduced in: v3.10.5
A --foxx.enable startup option has been added to let you configure whether
access to user-defined Foxx services is possible for the instance. It defaults
to true.
If you set the option to false, access to Foxx services is forbidden and is
responded with an HTTP 403 Forbidden error. Access to the management APIs for
Foxx services are also disabled as if you set --foxx.api false manually.
Access to ArangoDB’s built-in web interface, which is also a Foxx service, is
still possible even with the option set to false.
Disabling the access to Foxx can be useful to close off a potential attack vector in case Foxx is not used. Also see Server security options.
RocksDB auto-flushing
Introduced in: v3.9.10, v3.10.5
A new feature for automatically flushing RocksDB Write-Ahead Log (WAL) files and in-memory column family data has been added.
An auto-flush occurs if the number of live WAL files exceeds a certain threshold.
This ensures that WAL files are moved to the archive when there are a lot of
live WAL files present, for example, after a restart. In this case, RocksDB does
not count any previously existing WAL files when calculating the size of WAL
files and comparing its max_total_wal_size. Auto-flushing fixes this problem,
but may prevent WAL files from being moved to the archive quickly.
You can configure the feature via the following new startup options:
--rocksdb.auto-flush-min-live-wal-files: The minimum number of live WAL files that triggers an auto-flush. Defaults to10.--rocksdb.auto-flush-check-interval: The interval (in seconds) in which auto-flushes are executed. Defaults to3600. Note that an auto-flush is only executed if the number of live WAL files exceeds the configured threshold and the last auto-flush is longer ago than the configured auto-flush check interval. This avoids too frequent auto-flushes.
Configurable whitespace in metrics
Introduced in: v3.10.6
The output format of the metrics API slightly changed in v3.10.0. It no longer had a space between the label and the value for metrics with labels. Example:
arangodb_agency_cache_callback_number{role="SINGLE"}0
The new --server.ensure-whitespace-metrics-format startup option lets you
control whether the metric label and value shall be separated by a space for
improved compatibility with some tools. This option is enabled by default.
From v3.10.6 onward, the default output format looks like this:
arangodb_agency_cache_callback_number{role="SINGLE"} 0
Configurable interval when counting open file descriptors
Introduced in: v3.10.7
The --server.count-descriptors-interval startup option can be used to specify
the update interval in milliseconds when counting the number of open file
descriptors.
The default value is 60000, i.e. the update interval is once per minute.
To disable the counting of open file descriptors, you can set the value to 0.
If counting is turned off, the arangodb_file_descriptors_current metric
reports a value of 0.
Configurable limit of collections per query
Introduced in: v3.10.7, v3.11.1
The --query.max-collections-per-query startup option allows you to adjust the
previously fixed limit for the maximum number of collections/shards per AQL query.
The default value is 2048, which is equal to the fixed limit of
collections/shards in older versions.
Custom arguments to rclone
Introduced in: v3.9.11, v3.10.7, v3.11.1
The --rclone.argument startup option can be used to prepend custom arguments
to rclone. For example, you can enable debug logging to a separate file on
startup as follows:
arangod --rclone.argument "--log-level=DEBUG" --rclone.argument "--log-file=rclone.log"
LZ4 compression for values in the in-memory edge cache
Introduced in: v3.11.2
LZ4 compression of edge index cache values allows to store more data in main memory than without compression, so the available memory can be used more efficiently. The compression is transparent and does not require any change to queries or applications. The compression can add CPU overhead for compressing values when storing them in the cache, and for decompressing values when fetching them from the cache.
The new startup option --cache.min-value-size-for-edge-compression can be
used to set a threshold value size for compression edge index cache payload
values. The default value is 1GB, which effectively turns compression
off. Setting the option to a lower value (i.e. 100) turns on the
compression for any payloads whose size exceeds this value.
The new startup option --cache.acceleration-factor-for-edge-compression can
be used to fine-tune the compression. The default value is 1.
Higher values typically mean less compression but faster speeds.
The following new metrics can be used to determine the usefulness of compression:
rocksdb_cache_edge_inserts_effective_entries_size_total: returns the total number of bytes of all entries that were ever stored in the in-memory edge cache, after compression was attempted/applied. This metric is populated regardless of whether compression is used or not.rocksdb_cache_edge_inserts_uncompressed_entries_size_total: returns the total number of bytes of all entries that were ever stored in the in-memory edge cache, before compression was applied. This metric is populated regardless of whether compression is used or not.rocksdb_cache_edge_compression_ratio: returns the effective compression ratio for all edge cache entries ever stored in the cache.
Note that these metrics are increased upon every insertion into the edge cache, but not decreased when data gets evicted from the cache.
Limit the number of databases in a deployment
Introduced in: v3.10.10, v3.11.2
The --database.max-databases startup option allows you to limit the
number of databases that can exist in parallel in a deployment. You can use this
option to limit the resources used by database objects. If the option is used
and there are already as many databases as configured by this option, any
attempt to create an additional database fails with error
32 (ERROR_RESOURCE_LIMIT). Additional databases can then only be created
if other databases are dropped first. The default value for this option is
unlimited, so an arbitrary amount of databases can be created.
Cluster-internal connectivity checks
Introduced in: v3.11.5
This feature makes Coordinators and DB-Servers in a cluster periodically send check requests to each other, in order to see if all nodes can connect to each other. If a cluster-internal connection to another Coordinator or DB-Server cannot be established within 10 seconds, a warning is now logged.
The new --cluster.connectivity-check-interval startup option can be used
to control the frequency of the connectivity check, in seconds.
If set to a value greater than zero, the initial connectivity check is
performed approximately 15 seconds after the instance start, and subsequent
connectivity checks are executed with the specified frequency.
If set to 0, connectivity checks are disabled.
You can also use the following metrics to monitor and detect temporary or permanent connectivity issues:
arangodb_network_connectivity_failures_coordinators: Number of failed connectivity check requests sent by this instance to Coordinators.arangodb_network_connectivity_failures_dbservers_total: Number of failed connectivity check requests sent to DB-Servers.
Configurable maximum for queued log entries
Introduced in: v3.10.12, v3.11.5
The new --log.max-queued-entries startup option lets you configure how many
log entries are queued in a background thread.
Log entries are pushed on a queue for asynchronous writing unless you enable the
--log.force-direct startup option. If you use a slow log output (e.g. syslog),
the queue might grow and eventually overflow.
You can configure the upper bound of the queue with this option. If the queue is full, log entries are written synchronously until the queue has space again.
Monitoring per collection/database/user
Introduced in: v3.10.13, v3.11.7
The following metrics have been introduced to track per-shard requests on DB-Servers:
arangodb_collection_leader_reads_total: The number of read requests on leaders, per shard, and optionally also split by user.arangodb_collection_leader_writes_total: The number of write requests on leaders, per shard, and optionally also split by user.arangodb_collection_requests_bytes_read_total: The number of bytes read in read requests on leaders.arangodb_collection_requests_bytes_written_total: The number of bytes written in write requests on leaders and followers.
To opt into these metrics, you can use the new --server.export-shard-usage-metrics
startup option. It can be set to one of the following values on DB-Servers:
disabled: No shard usage metrics are recorded nor exported. This is the default value.enabled-per-shard: This makes DB-Servers collect per-shard usage metrics.enabled-per-shard-per-user: This makes DB-Servers collect per-shard and per-user metrics. This is more granular thanenabled-per-shardbut can produce a lot of metrics.
Whenever a shard is accessed in read or write mode by one of the following operations, the metrics are populated dynamically, either with a per-user label or not, depending on the above setting. The metrics are retained in memory on DB-Servers. Removing databases, collections, or users that are already included in the metrics won’t remove the metrics until the DB-Server is restarted.
The following operations increase the metrics:
- AQL queries: an AQL query increases the read or write counters exactly once for each involved shard. For shards that are accessed in read/write mode, only the write counter is increased.
- Single-document insert, update, replace, and remove operations: for each such operation, the write counter is increased once for the affected shard.
- Multi-document insert, update, replace, and remove operations: for each such operation, the write counter is increased once for each shard that is affected by the operation. Note that this includes collection truncate operations.
- Single and multi-document read operations: for each such operation, the read counter is increased once for each shard that is affected by the operation.
The metrics are increased when any of the above operations start, and they are not decreased should an operation abort or if an operation does not lead to any actual reads or writes.
As there can be many of these dynamic metrics based on the number of shards
and/or users in the deployment, these metrics are turned off by default.
When turned on, the metrics are exposed only via the new
GET /_admin/usage-metrics endpoint. They are not exposed via the existing
metrics GET /_admin/metrics endpoint.
Note that internal operations, such as internal queries executed for statistics gathering, internal garbage collection, and TTL index cleanup are not counted in these metrics. Additionally, all requests that are using the superuser JWT for authentication and that do not have a specific user set are not counted.
Enabling these metrics can likely result in a small latency overhead of a few percent for write operations. The exact overhead depends on several factors, such as the type of operation (single or multi-document operation), replication factor, network latency, etc.
Miscellaneous changes
Write-write conflict improvements
It is now less likely that writes to the same document in quick succession result in write-write conflicts for single document operations that use the Document HTTP API. See Incompatible changes in ArangoDB 3.11 about the detailed behavior changes.
Trace logs for graph traversals and path searches
Detailed information is now logged if you run AQL graph traversals
or (shortest) path searches with AQL and set the
log level to TRACE for the graphs log topic. This information is fairly
low-level but can help to understand correctness and performance issues with
traversal queries. There are also some new log messages for the DEBUG level.
To enable tracing for traversals and path searches at startup, you can set
--log.level graphs=trace.
To enable or disable it at runtime, you can call the
PUT /_admin/log/level
endpoint of the HTTP API and set the log level using a request body like
{"graphs":"TRACE"}.
Persisted Pregel execution statistics
Pregel algorithm executions now persist execution statistics to a system collection. The statistics are kept until you remove them, whereas the previously existing interfaces only store the information about Pregel jobs temporarily in memory.
To access and delete persisted execution statistics, you can use the newly added
history() and removeHistory() JavaScript API methods of the Pregel module:
var pregel = require("@arangodb/pregel");
const execution = pregel.start("sssp", "demograph", { source: "vertices/V" });
const historyStatus = pregel.history(execution);
pregel.removeHistory();See Distributed Iterative Graph Processing (Pregel) for details.
You can also use the newly added HTTP endpoints with the
/_api/control_pregel/history route.
See Pregel HTTP API for details.
You can still use the old interfaces (the pregel.status() method as well as
the GET /_api/control_pregel and GET /_api/control_pregel/{id} endpoints).
ArangoSearch metric
The following ArangoSearch metric has been added in version 3.11:
| Label | Description |
|---|---|
arangodb_search_num_primary_docs | Number of primary documents for current snapshot. |
Traffic accounting metrics
Introduced in: v3.8.9, v3.9.6, v3.10.2
The following metrics for traffic accounting have been added:
| Label | Description |
|---|---|
arangodb_client_user_connection_statistics_bytes_received | Bytes received for requests, only user traffic. |
arangodb_client_user_connection_statistics_bytes_sent | Bytes sent for responses, only user traffic. |
arangodb_http1_connections_total | Total number of HTTP/1.1 connections accepted. |
Configurable CACHE_OBLIVIOUS option for jemalloc
Introduced in: v3.9.7, v3.10.3
The jemalloc memory allocator supports an option to toggle cache-oblivious large allocation alignment. It is enabled by default up to v3.10.3, but disabled from v3.10.4 onwards. Disabling it helps to save 4096 bytes of memory for every allocation which is at least 16384 bytes large. This is particularly beneficial for the RocksDB buffer cache.
You can now configure the option by setting a CACHE_OBLIVIOUS environment
variable to the string true or false before starting ArangoDB.
See ArangoDB Server environment variables for details.
WAL file tracking metrics
Introduced in: v3.9.10, v3.10.5
The following metrics for write-ahead log (WAL) file tracking have been added:
| Label | Description |
|---|---|
rocksdb_live_wal_files | Number of live RocksDB WAL files. |
rocksdb_wal_released_tick_flush | Lower bound sequence number from which WAL files need to be kept because of external flushing needs. |
rocksdb_wal_released_tick_replication | Lower bound sequence number from which WAL files need to be kept because of replication. |
arangodb_flush_subscriptions | Number of currently active flush subscriptions. |
Number of replication clients metric
Introduced in: v3.10.5
The following metric for the number of replication clients for a server has been added:
| Label | Description |
|---|---|
arangodb_replication_clients | Number of currently connected/active replication clients. |
Reduced memory usage of in-memory edge indexes
Introduced in: v3.10.5
The memory usage of in-memory edge index caches is reduced if most of the edges in an index refer to a single or mostly the same collection.
Previously, the full edge IDs, consisting of the referred-to collection
name and the referred-to key of the edge, were stored in full, i.e. the full
values of the edges’ _from and _to attributes.
Now, the first edge inserted into an edge index’ in-memory cache determines
the collection name for which all corresponding edges can be stored
prefix-compressed.
For example, when inserting an edge pointing to the-collection/abc into the
empty cache, the collection name the-collection is noted for that cache
as a prefix. The edge is stored in-memory as only /abc. Further edges
that are inserted into the cache and that point to the same collection are
also stored prefix-compressed.
The prefix compression is transparent and does not require configuration or
setup. Compression is done separately for each cache, i.e. a separate prefix
can be used for each individual edge index, and separately for the _from and
_to parts. Lookups from the in-memory edge cache do not return compressed
values but the full-length edge IDs. The compressed values are also used
in-memory only and are not persisted on disk.
Sending delay metrics for internal requests
Introduced in: v3.9.11, v3.10.6
The following metrics for diagnosing delays in cluster-internal network requests have been added:
| Label | Description |
|---|---|
arangodb_network_dequeue_duration | Internal request duration for the dequeue in seconds. |
arangodb_network_response_duration | Internal request duration from fully sent till response received in seconds. |
arangodb_network_send_duration | Internal request send duration in seconds. |
arangodb_network_unfinished_sends_total | Number of internal requests for which sending has not finished. |
Peak memory metric for in-memory caches
Introduced in: v3.10.7
This new metric stores the peak value of the rocksdb_cache_allocated metric:
| Label | Description |
|---|---|
rocksdb_cache_peak_allocated | Global peak memory allocation of ArangoDB in-memory caches. |
Number of SST files metric
Introduced in: v3.10.7, v3.11.1
This new metric reports the number of RocksDB .sst files:
| Label | Description |
|---|---|
rocksdb_total_sst_files | Total number of RocksDB sst files, aggregated over all levels. |
File descriptor metrics
Introduced in: v3.10.7
The following system metrics have been added:
| Label | Description |
|---|---|
arangodb_file_descriptors_limit | System limit for the number of open files for the arangod process. |
arangodb_file_descriptors_current | Number of file descriptors currently opened by the arangod process. |
More instant Hot Backups
Introduced in: v3.10.10, v3.11.3
Cluster deployments no longer wait for all in-progress transactions to get committed when a user requests a Hot Backup. The waiting could cause deadlocks and thus Hot Backups to fail, in particular in ArangoGraph. Now, Hot Backups are created immediately and commits have to wait until the backup process is done.
In-memory edge cache startup options and metrics
Introduced in: v3.11.4
The following startup options have been added:
--cache.max-spare-memory-usage: the maximum memory usage for spare tables in the in-memory cache.--cache.high-water-multiplier: controls the cache’s effective memory usage limit. The user-defined memory limit (i.e.--cache.size) is multiplied with this value to create the effective memory limit, from which on the cache tries to free up memory by evicting the oldest entries. The default value is0.56, matching the previously hardcoded 56% for the cache subsystem.You can increase the multiplier to make the cache subsystem use more memory, but this may overcommit memory because the cache memory reclamation procedure is asynchronous and can run in parallel to other tasks that insert new data. In case a deployment’s memory usage is already close to the maximum, increasing the multiplier can lead to out-of-memory (OOM) kills.
The following metrics have been added:
| Label | Description |
|---|---|
rocksdb_cache_edge_compressed_inserts_total | Total number of compressed inserts into the in-memory edge cache. |
rocksdb_cache_edge_empty_inserts_total | Total number of insertions into the in-memory edge cache for non-connected edges. |
rocksdb_cache_edge_inserts_total | Total number of insertions into the in-memory edge cache. |
Observability of in-memory cache subsystem
Introduced in: v3.10.11, v3.11.4
The following metrics have been added to improve the observability of in-memory cache subsystem:
rocksdb_cache_free_memory_tasks_total: Total number of free memory tasks that were scheduled by the in-memory edge cache subsystem. This metric will be increased whenever the cache subsystem schedules a task to free up memory in one of the managed in-memory caches. It is expected to see this metric rising when the cache subsystem hits its global memory budget.rocksdb_cache_free_memory_tasks_duration_total: Total amount of time spent inside the free memory tasks of the in-memory cache subsystem. Free memory tasks are scheduled by the cache subsystem to free up memory in existing cache hash tables.rocksdb_cache_migrate_tasks_total: Total number of migrate tasks that were scheduled by the in-memory edge cache subsystem. This metric will be increased whenever the cache subsystem schedules a task to migrate an existing cache hash table to a bigger or smaller size.rocksdb_cache_migrate_tasks_duration_total: Total amount of time spent inside the migrate tasks of the in-memory cache subsystem. Migrate tasks are scheduled by the cache subsystem to migrate existing cache hash tables to a bigger or smaller table.
Detached scheduler threads
Introduced in: v3.10.13, v3.11.5
A scheduler thread now has the capability to detach itself from the scheduler if it observes the need to perform a potentially long running task, like waiting for a lock. This allows a new scheduler thread to be started and prevents scenarios where all threads are blocked waiting for a lock, which has previously led to deadlock situations.
Threads waiting for more than 1 second on a collection lock will detach themselves.
The following startup option has been added:
--server.max-number-detached-threads: The maximum number of detached scheduler threads.
The following metric has been added:
arangodb_scheduler_num_detached_threads: The number of worker threads currently started and detached from the scheduler.
Memory usage of connection and request statistics
Introduced in: v3.10.12, v3.11.6
The following metrics have been added:
| Label | Description |
|---|---|
arangodb_connection_statistics_memory_usage | Total memory usage of connection statistics. |
arangodb_request_statistics_memory_usage | Total memory usage of request statistics. |
If the --server.statistics startup option is set to true, then some
connection and request statistics are built up in memory for incoming request.
It is expected that the memory usage reported by these metrics remains
relatively constant over time. It may grow only when there are bursts of new
connections. Some memory is pre-allocated at startup for higher efficiency. If the
--server.statistics startup option is set to false, then no memory will be
allocated for connection and request statistics.
Client tools
arangodump
Option to not dump Views
arangodump has a new --dump-views startup option to control whether
View definitions shall be included in the backup. The default value is true.
Improved dump performance (experimental)
Introduced in: v3.10.8, v3.11.2
arangodump has experimental extended parallelization capabilities to work not only at the collection level, but also at the shard level. In combination with the newly added support for the VelocyPack format that ArangoDB uses internally, database dumps can now be created and restored more quickly and occupy less disk space. This major performance boost makes dumps and restores up to several times faster, which is extremely useful when dealing with large shards.
Whether the new parallel dump variant is used is controlled by the newly added
--use-experimental-dumpstartup option (introduced in v3.10.8 and v3.11.2). The default value isfalse.Optionally, you can make arangodump write multiple output files per collection/shard (introduced in v3.10.10 and v3.11.2). The file splitting allows for better parallelization when writing the results to disk, which in case of non-split files must be serialized. You can enable it by setting the
--split-filesoption totrue. This option is disabled by default because dumps created with this option enabled cannot be restored into previous versions of ArangoDB.
Internal changes
Upgraded bundled library versions
The bundled version of the OpenSSL library has been upgraded from 1.1.1 to 3.0.8.
The bundled version of the zlib library has been upgraded to 1.2.13.
The bundled version of the fmt library has been upgraded to 9.1.0.
The bundled version of the immer library has been upgraded to 0.8.0.
The bundled versions of the abseil-cpp, s2geometry, and wcwidth library have been updated to more recent versions that don’t have a version number.
For ArangoDB 3.11, the bundled version of rclone is 1.62.2. Check if your rclone configuration files require changes.
From version 3.11.10 onward, ArangoDB uses the glibc C standard library implementation with an LGPL-3.0 license instead of libmusl. Notably, it features string functions that are better optimized for common CPUs.