Sharding
ArangoDB can divide collections into multiple shards to distribute the data across multiple cluster nodes
ArangoDB organizes its collection data in shards. Sharding allows you to use multiple machines to run a cluster of ArangoDB instances that together constitute a single database system.
Sharding is used to distribute data across physical machines in an ArangoDB Cluster. It is a method to determine the optimal placement of documents on individual DB-Servers.
This enables you to store much more data, since ArangoDB distributes the data automatically to the different servers. In many situations one can also reap a benefit in data throughput, again because the load can be distributed to multiple machines.
Using sharding allows ArangoDB to support deployments with large amounts of data, which would not fit on a single machine. A high rate of write / read operations or AQL queries can also overwhelm a single servers RAM and disk capacity.
There are two main ways of scaling a database system:
- Vertical scaling
- Horizontal scaling
Vertical scaling means to upgrade to better server hardware (faster CPU, more RAM / disk). This can be a cost effective way of scaling, because administration is easy and performance characteristics do not change much. Reasoning about the behavior of a single machine is also a lot easier than having multiple machines. However at a certain point larger machines are either not available anymore or the cost becomes prohibitive.
Horizontal scaling is about increasing the number of servers. Servers typically being based on commodity hardware, which is readily available from many different Cloud providers. The capability of each single machine may not be high, but the combined the computing power of these machines can be arbitrarily large. Adding more machines on-demand is also typically easier and more cost-effective than pre-provisioning a single large machine. Increased complexity in infrastructure can be managed using modern containerization and cluster orchestrations tools like Kubernetes.
To achieve this ArangoDB splits your dataset into so called shards. The number of shards is something you may choose according to your needs. Proper sharding is essential to achieve optimal performance. From the outside the process of splitting the data and assembling it again is fully transparent and as such we achieve the goals of what other systems call “master-master replication”.
An application may talk to any Coordinator and it automatically figures out where the data is currently stored when reading or is to be stored when writing. The information about the shards is shared across all Coordinators using the Agency.
Shards are configured per collection so multiple shards of data form the
collection as a whole. To determine in which shard the data is to be stored
ArangoDB performs a hash across the values. By default this hash is being
created from the _key document attribute.
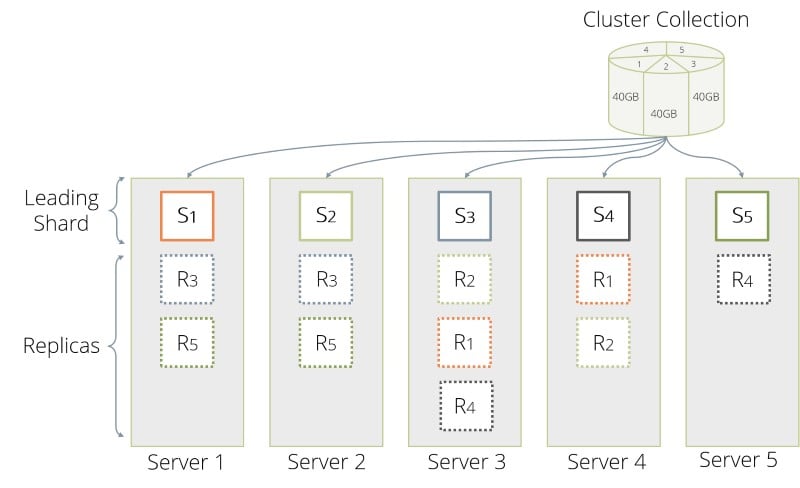
Every shard is a local collection on any DB-Server, that houses such a shard as depicted above for our example with 5 shards and 3 replicas. Here, every leading shard S1 through S5 is followed each by 2 replicas R1 through R5. The collection creation mechanism on ArangoDB Coordinators tries to best distribute the shards of a collection among the DB-Servers. This seems to suggest, that one shards the data in 5 parts, to make best use of all our machines. We further choose a replication factor of 3 as it is a reasonable compromise between performance and data safety. This means, that the collection creation ideally distributes 15 shards, 5 of which are leaders to each 2 replicas. This in turn implies, that a complete pristine replication would involve 10 shards which need to catch up with their leaders.
Not all use cases require horizontal scalability. In such cases, consider the OneShard feature as alternative to flexible sharding.
Shard Keys
ArangoDB uses the specified shard key attributes to determine in which shard a given document is to be stored. Choosing the right shard key can have significant impact on your performance can reduce network traffic and increase performance.
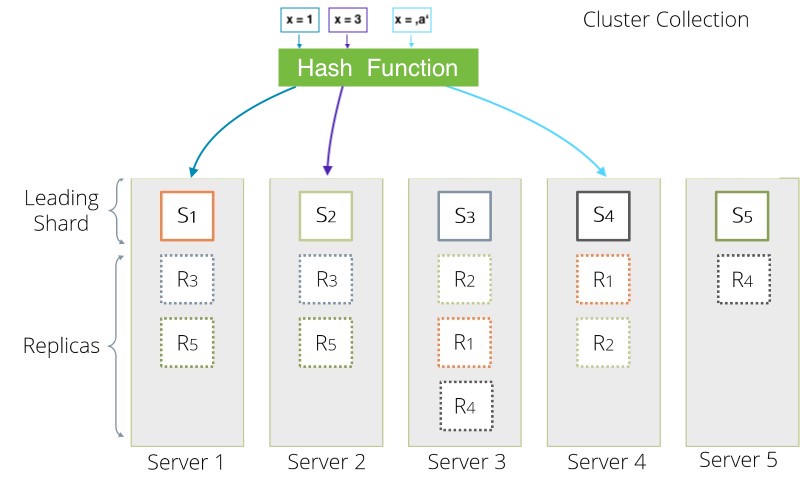
ArangoDB uses consistent hashing to compute the target shard from the given
values (as specified via by the shardKeys collection property). The ideal set
of shard keys allows ArangoDB to distribute documents evenly across your shards
and your DB-Servers. By default ArangoDB uses the _key field as a shard key.
For a custom shard key you should consider a few different properties:
Cardinality: The cardinality of a set is the number of distinct values that it contains. A shard key with only N distinct values cannot be hashed onto more than N shards. Consider using multiple shard keys, if one of your values has a low cardinality.
Frequency: Consider how often a given shard key value may appear in your data. Having a lot of documents with identical shard keys leads to unevenly distributed data.
This means that a single shard could become a bottleneck in your cluster. The effectiveness of horizontal scaling is reduced if most documents end up in a single shard. Shards are not divisible at this time, so paying attention to the size of shards is important.
Consider both frequency and cardinality when picking a shard key, if necessary consider picking multiple shard keys.
Configuring Shards
The number of shards can be configured at collection creation time, e.g. in the web interface or via arangosh:
db._create("sharded_collection", {"numberOfShards": 4, "shardKeys": ["country"]});The example above, where country has been used as shardKeys can be useful
to keep data of every country in one shard, which would result in better
performance for queries working on a per country base.
It is also possible to specify multiple shardKeys.
Note however that if you change the shard keys from their default ["_key"],
then finding a document in the collection by its primary key involves a request
to every single shard. However this can be mitigated: All CRUD APIs and AQL
support using the shard key values as a lookup hints. Just send them as part
of the update / replace or removal operation, or in case of AQL, that
you use a document reference or an object for the UPDATE, REPLACE or REMOVE
operation which includes the shard key attributes:
UPDATE { _key: "123", country: "…" } WITH { … } IN sharded_collectionIf custom shard keys are used, one can no longer prescribe the primary key value of a new document but must use the automatically generated one. This latter restriction comes from the fact that ensuring uniqueness of the primary key would be very inefficient if the user could specify the primary key.
On which DB-Server in a Cluster a particular shard is kept is undefined. There is no option to configure an affinity based on certain shard keys.
For more information on shard rebalancing and administration topics please have a look in the Cluster Administration section.
Indexes On Shards
Unique indexes on sharded collections are only allowed if the fields used to determine the shard key are also included in the list of attribute paths for the index:
| shardKeys | indexKeys | |
|---|---|---|
| a | a | allowed |
| a | b | not allowed |
| a | a, b | allowed |
| a, b | a | not allowed |
| a, b | b | not allowed |
| a, b | a, b | allowed |
| a, b | a, b, c | allowed |
| a, b, c | a, b | not allowed |
| a, b, c | a, b, c | allowed |
High Availability
A cluster can still read from a collection if shards become unavailable for some reason. The data residing on the unavailable shard cannot be accessed, but reads on other shards can still succeed.
If you enable data redundancy by setting a replication factor of 2 or higher
for a collection, the collection data remains fully available for reading as
long as at least one replica of every shard is available.
In a production environment, you should always deploy your collections with a
replicationFactor greater than 1 to ensure that the shards stay available
even when a machine fails.
Collection data also remains available for writing as long as a replica of every
shard is available. You can optionally increase the write concern to require a
higher number of in-sync shard replicas for writes. The writeConcern can be
as high as the replicationFactor.
Storage Capacity
The cluster distributes your data across multiple machines in your cluster. Every machine only contains a subset of your data. Thus, the cluster has the combined storage capacity of all your machines.
Please note that increasing the replication factor also increases the space required to keep all your data in the cluster.