Cluster deployments
ArangoDB clusters are composed of DB-Servers, Coordinators, and Agents, with synchronous data replication between DB-Servers and automatic failover
The Cluster architecture of ArangoDB is a CP master/master model with no single point of failure.
With “CP” in terms of the CAP theorem we mean that in the presence of a network partition, the database prefers internal consistency over availability. With “master/master” we mean that clients can send their requests to an arbitrary node, and experience the same view on the database regardless. “No single point of failure” means that the cluster can continue to serve requests, even if one machine fails completely.
In this way, ArangoDB has been designed as a distributed multi-model database. This section gives a short outline on the Cluster architecture and how the above features and capabilities are achieved.
Structure of an ArangoDB Cluster
An ArangoDB Cluster consists of a number of ArangoDB instances which talk to each other over the network. They play different roles, which are explained in detail below.
The current configuration of the Cluster is held in the Agency, which is a highly-available resilient key/value store based on an odd number of ArangoDB instances running Raft Consensus Protocol .
For the various instances in an ArangoDB Cluster there are three distinct roles:
- Agents
- Coordinators
- DB-Servers.
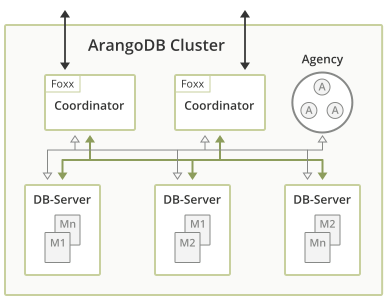
Agents
One or multiple Agents form the Agency in an ArangoDB Cluster. The Agency is the central place to store the configuration in a Cluster. It performs leader elections and provides other synchronization services for the whole Cluster. Without the Agency none of the other components can operate.
While generally invisible to the outside the Agency is the heart of the Cluster. As such, fault tolerance is of course a must have for the Agency. To achieve that the Agents are using the Raft Consensus Algorithm . The algorithm formally guarantees conflict free configuration management within the ArangoDB Cluster.
At its core the Agency manages a big configuration tree. It supports transactional read and write operations on this tree, and other servers can subscribe to HTTP callbacks for all changes to the tree.
Coordinators
Coordinators should be accessible from the outside. These are the ones the clients talk to. They coordinate cluster tasks like executing queries and running Foxx services. They know where the data is stored and optimize where to run user-supplied queries or parts thereof. Coordinators are stateless and can thus easily be shut down and restarted as needed.
DB-Servers
DB-Servers are the ones where the data is actually hosted. They host shards of data and using synchronous replication a DB-Server may either be leader or follower for a shard. Document operations are first applied on the leader and then synchronously replicated to all followers.
Shards must not be accessed from the outside but indirectly through the Coordinators. They may also execute queries in part or as a whole when asked by a Coordinator.
See Sharding below for more information.
Many sensible configurations
This architecture is very flexible and thus allows many configurations, which are suitable for different usage scenarios:
- The default configuration is to run exactly one Coordinator and one DB-Server on each machine. This achieves the classical master/master setup, since there is a perfect symmetry between the different nodes, clients can equally well talk to any one of the Coordinators and all expose the same view to the data store. Agents can run on separate, less powerful machines.
- One can deploy more Coordinators than DB-Servers. This is a sensible approach if one needs a lot of CPU power for the Foxx services, because they run on the Coordinators.
- One can deploy more DB-Servers than Coordinators if more data capacity is needed and the query performance is the lesser bottleneck
- One can deploy a Coordinator on each machine where an application server (e.g. a node.js server) runs, and the Agents and DB-Servers on a separate set of machines elsewhere. This avoids a network hop between the application server and the database and thus decreases latency. Essentially, this moves some of the database distribution logic to the machine where the client runs.
As you can see, the Coordinator layer can be scaled and deployed independently from the DB-Server layer.
It is a best practice and a recommended approach to run Agent instances on different machines than DB-Server instances.
When deploying using the tool Starter
this can be achieved by using the options --cluster.start-dbserver=false and
--cluster.start-coordinator=false on the first three machines where the Starter
is started, if the desired Agency size is 3, or on the first 5 machines
if the desired Agency size is 5.
Sharding
Using the roles outlined above an ArangoDB Cluster is able to distribute data in so called shards across multiple DB-Servers. Sharding allows you to use multiple machines to run a cluster of ArangoDB instances that together constitute a single database. This enables you to store much more data, since ArangoDB distributes the data automatically to the different servers. In many situations one can also reap a benefit in data throughput, again because the load can be distributed to multiple machines.
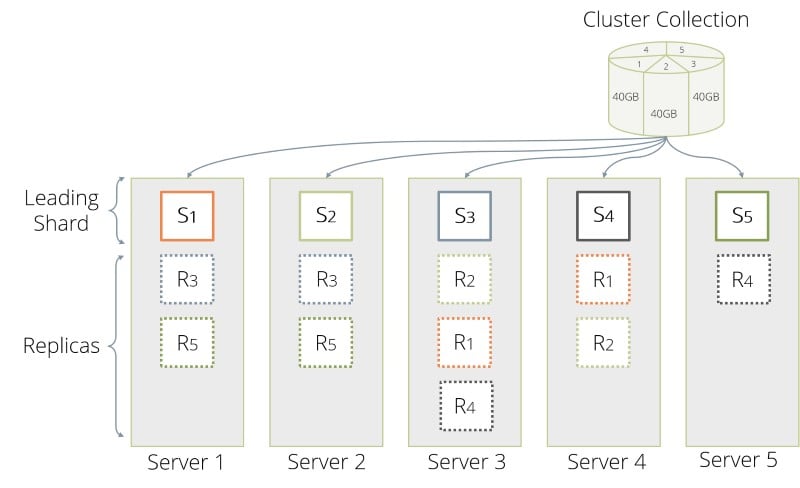
From the outside this process is fully transparent: An application may talk to any Coordinator and it automatically figures out where the data is currently stored when reading or is to be stored when writing. The information about the shards is shared across all Coordinators using the Agency.
Shards are configured per collection so multiple shards of data form the collection as a whole. To determine in which shard the data is to be stored ArangoDB performs a hash across the values. By default this hash is being created from the document _key.
For further information, please refer to the Cluster Sharding section.
OneShard
A OneShard deployment offers a practicable solution that enables significant performance improvements by massively reducing cluster-internal communication and allows running transactions with ACID guarantees on shard leaders.
For more information, please refer to the OneShard chapter.
Synchronous replication
In an ArangoDB Cluster, the replication among the data stored by the DB-Servers is synchronous.
Synchronous replication works on a per-shard basis. Using the replicationFactor
option, you can configure for each collection how many copies of each shard
are kept in the Cluster.
If a collection has a replication factor of 1, its data is not
replicated to other DB-Servers. This exposes you to a risk of data loss, if
the machine running the DB-Server with the only copy of the data fails permanently.
You need to set the replication factor to a value equal or higher than 2
to achieve minimal data redundancy via the synchronous replication.
You need to set a replication factor equal to or higher than 2
explicitly when creating a collection, or you can adjust it later if you
forgot to set it at creation time. You can also enforce a
minimum replication factor for all collections by setting the
--cluster.min-replication-factor startup option.
When using a Cluster, please make sure all the collections that are important
(and should not be lost in any case) have a replication factor equal or higher
than 2.
At any given time, one of the copies is declared to be the leader and all other replicas are followers. Internally, write operations for this shard are always sent to the DB-Server which happens to hold the leader copy, which in turn replicates the changes to all followers before the operation is considered to be done and reported back to the Coordinator. Internally, read operations are all served by the DB-Server holding the leader copy, this allows you to provide snapshot semantics for complex transactions.
Using synchronous replication alone guarantees consistency and high availability at the cost of reduced performance: write requests have a higher latency (due to every write-request having to be executed on the followers) and read requests do not scale out as only the leader is being asked.
In a Cluster, synchronous replication is managed by the Coordinators for the client. The data is always stored on the DB-Servers.
The following example gives you an idea of how synchronous operation has been implemented in ArangoDB Cluster:
Connect to a Coordinator via arangosh
Create a collection:
db._create("test", {"replicationFactor": 2});The Coordinator figures out a leader and one follower and creates one shard (as this is the default)
Insert data:
db.test.insert({"foo": "bar"});The Coordinator writes the data to the leader, which in turn replicates it to the follower.
Only when both are successful, the result is reported indicating success:
{ "_id" : "test/7987", "_key" : "7987", "_rev" : "7987" }
Synchronous replication comes at the cost of an increased latency for write operations, simply because there is one more network hop within the Cluster for every request. Therefore the user can set the replicationFactor to 1, which means that only one copy of each shard is kept, thereby switching off synchronous replication. This is a suitable setting for less important or easily recoverable data for which low latency write operations matter.
Automatic failover
Failure of a follower
If a DB-Server that holds a follower copy of a shard fails, then the leader can no longer synchronize its changes to that follower. After a short timeout (3 seconds), the leader gives up on the follower and declares it to be out of sync.
One of the following two cases can happen:
A: If another DB-Server (that does not hold a replica for this shard already) is available in the Cluster, a new follower is automatically created on this other DB-Server (so the replication factor constraint is satisfied again).
B: If no other DB-Server (that does not hold a replica for this shard already) is available, the service continues with one follower less than the number prescribed by the replication factor.
If the old DB-Server with the follower copy comes back, one of the following two cases can happen:
Following case A, the DB-Server recognizes that there is a new follower that was elected in the meantime, so it is no longer a follower for that shard.
Following case B, the DB-Server automatically resynchronizes its data with the leader. The replication factor constraint is now satisfied again and order is restored.
Failure of a leader
If a DB-Server that holds a leader copy of a shard fails, then the leader can no longer serve any requests. It no longer sends a heartbeat to the Agency. Therefore, a supervision process running in the Raft leader of the Agency, can take the necessary action (after 15 seconds of missing heartbeats), namely to promote one of the DB-Servers that hold in-sync replicas of the shard to leader for that shard. This involves a reconfiguration in the Agency and leads to the fact that Coordinators now contact a different DB-Server for requests to this shard. Service resumes. The other surviving replicas automatically resynchronize their data with the new leader.
In addition to the above, one of the following two cases can happen:
A: If another DB-Server (that does not hold a replica for this shard already) is available in the Cluster, a new follower is automatically created on this other DB-Server (so the replication factor constraint is satisfied again).
B: If no other DB-Server (that does not hold a replica for this shard already) is available the service continues with one follower less than the number prescribed by the replication factor.
When the DB-Server with the original leader copy comes back, it recognizes that a new leader was elected in the meantime, and one of the following two cases can happen:
Following case A, since also a new follower was created and the replication factor constraint is satisfied, the DB-Server is no longer a follower for that shard.
Following case B, the DB-Server notices that it now holds a follower replica of that shard and it resynchronizes its data with the new leader. The replication factor constraint is satisfied again, and order is restored.
The following example gives you an idea of how failover has been implemented in ArangoDB Cluster:
- The leader of a shard (let’s name it DBServer001) is going down.
- A Coordinator is asked to return a document:
db.test.document("100069"); - The Coordinator determines which server is responsible for this document and finds DBServer001
- The Coordinator tries to contact DBServer001 and timeouts because it is not reachable.
- After a short while, the supervision (running in parallel on the Agency) sees that heartbeats from DBServer001 are not coming in
- The supervision promotes one of the followers (say DBServer002), that is in sync, to be leader and makes DBServer001 a follower.
- As the Coordinator continues trying to fetch the document, it sees that the leader changed to DBServer002
- The Coordinator tries to contact the new leader (DBServer002) and returns
the result:
{ "_key" : "100069", "_id" : "test/100069", "_rev" : "513", "foo" : "bar" } - After a while the supervision declares DBServer001 to be completely dead.
- A new follower is determined from the pool of DB-Servers.
- The new follower syncs its data from the leader and order is restored.
Please note that there may still be timeouts. Depending on when exactly the request has been done (in regard to the supervision) and depending on the time needed to reconfigure the Cluster the Coordinator might fail with a timeout error.
Shard movement and resynchronization
All shard data synchronizations are done in an incremental way, such that resynchronizations are quick. This technology allows you to move shards (follower and leader ones) between DB-Servers without service interruptions. Therefore, an ArangoDB Cluster can move all the data on a specific DB-Server to other DB-Servers and then shut down that server in a controlled way. This allows you to scale down an ArangoDB Cluster without service interruption, loss of fault tolerance or data loss. Furthermore, one can re-balance the distribution of the shards, either manually or automatically.
All these operations can be triggered via a REST/JSON API or via the graphical web interface. All fail-over operations are completely handled within the ArangoDB Cluster.
Microservices and zero administration
The design and capabilities of ArangoDB are geared towards usage in modern microservice architectures of applications. With the Foxx services it is very easy to deploy a data centric microservice within an ArangoDB Cluster.
In addition, one can deploy multiple instances of ArangoDB within the same project. One part of the project might need a scalable document store, another might need a graph database, and yet another might need the full power of a multi-model database actually mixing the various data models. There are enormous efficiency benefits to be reaped by being able to use a single technology for various roles in a project.
To simplify life of the devops in such a scenario we try as much as possible to use a zero administration approach for ArangoDB. A running ArangoDB Cluster is resilient against failures and essentially repairs itself in case of temporary failures.
Deployment
An ArangoDB Cluster can be deployed in several ways, e.g. by manually starting all the needed instances, by using the tool Starter, in Docker and in Kubernetes.
See the Cluster Deployment chapter for instructions.
ArangoDB is also available as a cloud service, the ArangoGraph Insights Platform .
Cluster ID
Every ArangoDB instance in a Cluster is assigned a unique ID during its startup. Using its ID, a node is identifiable throughout the Cluster. All cluster operations communicate via this ID.